苹果研究揭露顶级AI模型基础数学推理全面崩盘
苹果AI数学失败:顶级模型推理幻象的行业警钟
🔬 Tech Brief: 仅在小学数学题中多加一句看似无关的闲话,GPT-4o准确率就从95%暴跌至63.1%——苹果最新研究戳破了当前顶级AI“真正推理”的神话,暴露其本质仍是模式匹配。
📌 关键事实
– 事件时间:2024年10月,苹果机器学习研究团队发布论文
– 核心主体:苹果六位工程师(Iman Mirzadeh等),基于GSM8K基准创建GSM-Symbolic与GSM-NoOp变体
– 关键数据:添加一句无关但看似相关的句子后,25款顶尖模型准确率大幅下滑,GPT-4o跌至63.1%,部分模型最高降幅65%
– 研究结论:当前LLM无法进行真正逻辑推理,仅复制训练数据中的推理步骤
– 影响范围:涵盖GPT-4o、o1-preview、Llama系列等主流模型(来源:Apple Machine Learning Research)
事件还原
2024年10月,苹果研究团队在arXiv正式发布论文《GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models》。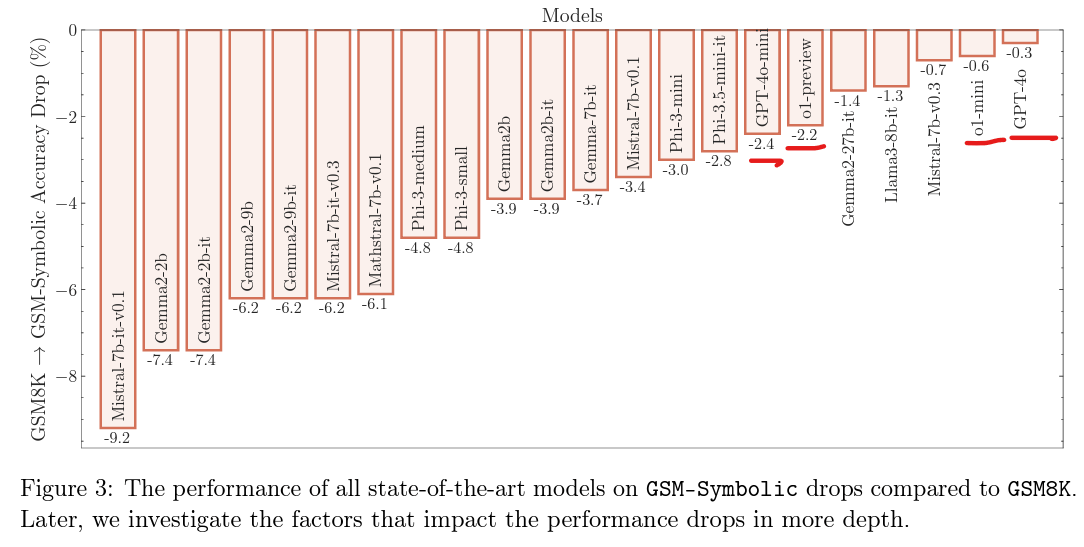
他们首先从经典GSM8K数据集出发,利用符号模板生成多样化问题,形成GSM-Symbolic基准;随后在GSM-NoOp实验中,向每道题额外插入一句看似相关却不影响最终答案的句子(如无关的“部分稍小”描述)。
测试覆盖25款顶尖模型,使用8-shot CoT提示。结果显示,所有模型在无关信息干扰下表现崩盘:GPT-4o准确率直接从GSM8K的约95%降至63.1%,o1-preview下降17.5%,部分开源模型降幅高达65%。论文明确指出,这些变化并未改变推理链条本身。(来源:arXiv论文PDF)
评论视角
这一事件从技术趋势角度直击当前AI行业的核心痛点:尽管o1等“推理模型”被大力宣传为突破,但苹果研究证明,它们仍高度依赖训练数据的模式匹配,而非形式化逻辑推理。
在芯片、互联网与AI竞赛白热化的今天,OpenAI、Google等巨头将大量资源投入“scaling law+链式思考”,却被苹果以低成本基准测试戳穿脆弱性。这不仅暴露基准污染与评估不严谨的问题,更提醒行业:没有真正可解释的推理能力,AI就难以在高风险场景立足。
“我们假设这种下降是因为当前LLM无法进行真正的逻辑推理;相反,它们试图复制训练数据中观察到的推理步骤。”
苹果虽未在消费级大模型上全面领跑,却通过独立研究保持了对AI基础能力的理性批判,这将重塑行业战略竞争格局。
影响预判
短期(6个月内):AI基准测试标准将迅速升级,企业被迫增加抗干扰评估(如更多NoOp变体),市场对“推理模型”宣传的信任暂时回落,可能导致融资节奏放缓与产品迭代优先级调整。
长期(3-5年):将加速神经符号混合架构、新型训练范式研发,推动AI从纯统计预测向真正逻辑融合转型;在教育、金融、医疗等可靠性要求高的领域,应用门槛提升,同时可能引发全球监管机构对AI可解释性提出更严格标准。
常见问题解答
❓ 苹果AI数学失败事件到底是什么?
苹果AI数学失败指2024年10月苹果研究团队在GSM8K基准中添加一句无关句子后,GPT-4o等25款顶级AI模型准确率集体大幅下滑(如GPT-4o跌至63.1%),论文证明当前大模型依赖模式匹配而非真正逻辑推理。(来源:[Apple官方研究页](https://machinelearning.apple.com/research/gsm-symbolic))
❓ 为什么这个事件对AI行业如此重要?
它直接挑战了行业对“大模型已具备推理能力”的主流叙事,暴露GSM8K等基准的可靠性缺陷,迫使从业者重新评估AI安全边界与实际落地潜力。
❓ 接下来AI行业趋势会如何发展?
短期内基准测试将更严苛,企业加速开发鲁棒性评估;长期将推动混合推理架构研发,真正逻辑能力成为下一代模型的核心竞争力,行业竞争焦点从规模转向可解释性。
❓ 这是否意味着AI无法实现AGI?
并非完全否定,但当前路径存在根本局限。事件提醒业界需探索新范式(如符号+神经融合),而非单纯依赖更大规模数据。
📅 本文信息更新至2026年4月7日,内容综合自X (Twitter) 实时热搜及权威科技媒体(如Apple Research、arXiv、Ars Technica)报道,仅供参考。





確實,AI其實不甚智能。但99.99%人類在99.99%的時候也不甚智能。比如像您這種連漢諾塔都不知道、翻譯成塔汉諾伊的搬運工,可以非常負責任地說早就應該被AI淘汰了。
(立场: 幽默 | 👍 14)
事实上现在苹果也无法证明,人类的所谓“推理”是否是建立在记忆模式之上的。很明显,人类的“推理”也受到该大脑所掌握的现有的知识的限制。
(立场: 中立 | 👍 0)
难怪苹果在这两年跟不上其他大厂的水平呢。复杂推理的解空间靠现有模型根本拟合不出来,很久之前就有论文说过了。2025年过去一半了,苹果还在做这种demo级别的研究。
(立场: 反对 | 👍 0)
要是具备真正的推理能力就可怕了…
(立场: 支持 | 👍 0)
这是去年的新闻吧
(立场: 中立 | 👍 0)